一、前言
新入职的公司用小米开发的 open-falcon来做监控,所以今天来学一下,相比于主流的 zabbix ,添加客户端时,open-falcon 不需要用户在server做任何配置,只要安装了falcon-agent的机器,就会自动开始采集各项指标,主动上报。这种方式用户维护方便,覆盖率高。当然这样做也会 server 端造成较大的压力。
二、open-falcon 特点
1.架构模块
open-falcon 的主要结构模块如下图: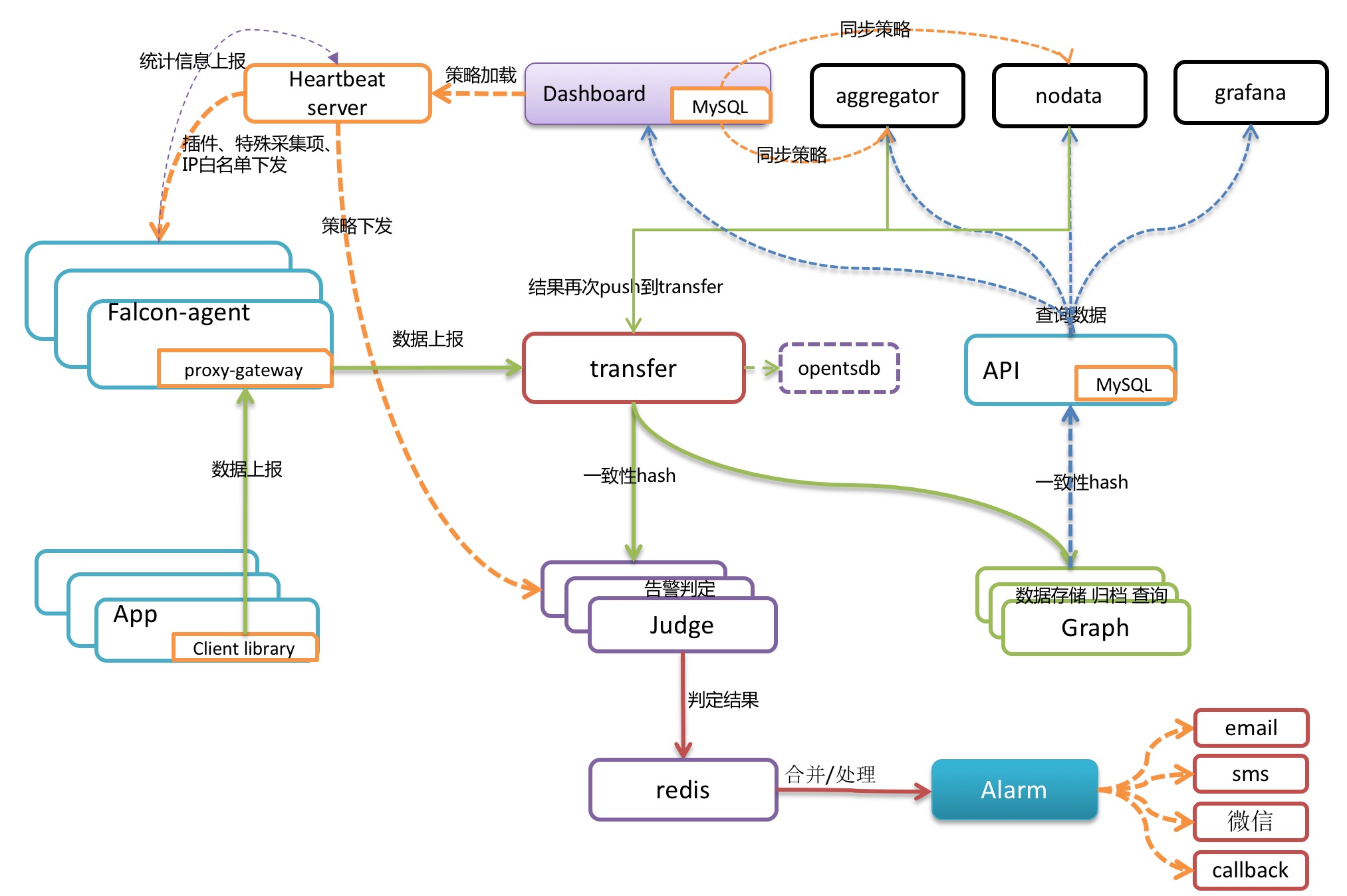
每台服务器,都有安装falcon-agent,falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标,这些指标包括不限于以下几个方面,共计200多项指标。
- CPU相关
- 磁盘相关
- IO
- Load
- 内存相关
- 网络相关
- 端口存活、进程存活
- ntp offset(插件)
- 某个进程资源消耗(插件)
- netstat、ss 等相关统计项采集
- 机器内核配置参数
2.数据模型
zabbix 对于不同的告警信息需要配置多条规则,open-falcon,采用和opentsdb相同的数据格式:metric、endpoint加多组key value tags,举两个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18{
metric: load.1min,
endpoint: open-falcon-host,
tags: srv=falcon,idc=aws-sgp,group=az1,
value: 1.5,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
{
metric: net.port.listen,
endpoint: open-falcon-host,
tags: port=3306,
value: 1,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
通过这样的数据结构,我们就可以从多个维度来配置告警,配置dashboard等等。 备注:endpoint是一个特殊的tag。
3.数据收集
transfer的数据来源,一般有三种:
- falcon-agent采集的基础监控数据
- falcon-agent执行用户自定义的插件返回的数据
- client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报
说明:上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer。
4.Dashboard
dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
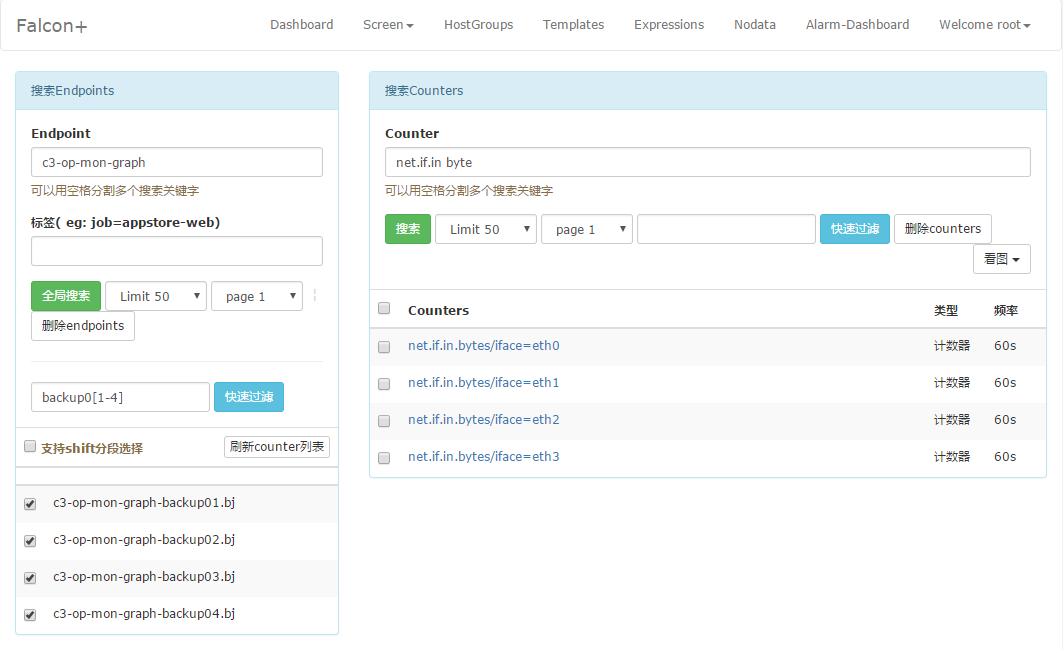
用户可以自定义多个metric,添加到某个screen中,所谓 metric 就是监控信息的基础单元。
5.存储
对于监控系统来说,数据存储是重中之重,历史数据量大,并且需要高效率的查询制图。
- 数据量非常大: 每个周期都有大量的数据需要采样。
- 大量的写操作: 相比与其他数据库,监控所用数据库有大量的写操作,每个周期几千万次的写入。
- 高效率的读: 虽然读数据操作相对较少,但是需要高效率的读,一般会一次性查询上百个metric
open-falcon 把数据按照用途分成两类,一类是用来绘图的,一类是用户做数据挖掘的。open-falcon 在数据每次存入的时候,会自动进行采样、归档。历史数据保存5年,同时为了不丢失信息量,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。
三、Open-falcon 部署
1.Server 后端安装
go 环境部署
- 下载 go 编译好的tar 包,https://golang.org/dl , 有可能会被墙
创建工作目录并解压下载好的 tar 包
1
2
3mkdir /software
mkdir gopath & cd gopath & mkdir src pkg bin # go 语言特性,需要这个目录
cd /software & tar -zxvf go1.9.linux-amd64.tar.gz # 会解压出 go 目录配置环境变量,检查是否安装成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23vim /etc/profile
export GOROOT=/software/go
export GOPATH=/software/gopath
export GOBIN=$GOPATH/bin
export PATH=$PATH:$GOBIN:$GOROOT/bin
go env
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/software/gopath"
GOPROXY=""
GORACE=""
GOROOT="/usr/lib/golang"
GOTMPDIR=""
GOTOOLDIR="/usr/lib/golang/pkg/tool/linux_amd64"
CC="gcc"
CGO_ENABLED="1"
...
如果是通过 yum 安装的 go ,可以在 profile 文件自定义GOPATH,注意要求 Go >= 1.6
mysql 数据库、redis 部署
提前安装好 mysql 后,使用 open-falcon 提供的sql 文件创建需要的数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22yum install mariadb mariadb-server
systemctl start mariadb
systemctl enable mariadb
mysql_secure_installation #初始化密码
//使用open-falcon 提供的脚本初始化数据库,编译好的tar 包里面没有,所有需要用git clone 一下
cd /software && git clone https://github.com/open-falcon/falcon-plus.git
cd /software/falcon-plus/scripts/mysql/db_schema/
[root@hadoop3 db_schema]# ll
total 24
-rw-r--r-- 1 root root 1952 Dec 19 20:00 1_uic-db-schema.sql
-rw-r--r-- 1 root root 7573 Dec 19 20:00 2_portal-db-schema.sql
-rw-r--r-- 1 root root 3391 Dec 19 20:00 3_dashboard-db-schema.sql
-rw-r--r-- 1 root root 1807 Dec 19 20:00 4_graph-db-schema.sql
mysql -h 127.0.0.1 -u root -p < 1_uic-db-schema.sql
mysql -h 127.0.0.1 -u root -p < 2_portal-db-schema.sql
mysql -h 127.0.0.1 -u root -p < 3_dashboard-db-schema.sql
mysql -h 127.0.0.1 -u root -p < 4_graph-db-schema.sql
mysql -h 127.0.0.1 -u root -p < 5_alarms-db-schema.sql安装redis ,开启服务
1
2
3
4yum install redis
systemctl enable redis
systemctl start redis
vim /etc/redis.conf # 如有需要编辑配置文件
安装 open-falcon 包
- 下载 open-falcon 编译好的tar 包,https://github.com/open-falcon/falcon-plus/releases
- 解压
1
2
3
4
5
6
7
8
9mkdir /software/open-falcon
tar -zxvf open-falcon-v0.2.1.tar.gz -C open-falcon
// 也可以直接使用 git 下来的 falcon-plus 目录 makefile 自己编译出tar 包
//make all && make agent && make pack
//后端启动
./open-falcon start
./open-falcon check
2.Server 前端 Dashboard 安装
使用 git 克隆 dashboard
1
2cd /software
git clone https://github.com/open-falcon/dashboard.git安装依赖包
1
2
3
4
5
6
7
8
9
10yum install -y python-virtualenv
yum install -y python-devel
yum install -y openldap-devel
yum install -y mysql-devel
yum groupinstall "Development tools"
cd /software/dashboard/
virtualenv ./env
./env/bin/pip install -r pip_requirements.txt修改 dashboard 配置文件rrd/config.py
启动前端,并访问前端展示页面
1
2
3bash control start
bash control stop
bash control tail访问 localhost:8081
3.agent 安装
agent 需要部署到所有要被监控的机器上,比如公司有10万台机器,那就要部署10万个agent。agent本身资源消耗很少,不用担心。
在server 端找到之前后端服务的解压目录,将目录下的 agent 拷贝到客户端
1
scp -r agent/ root@xxxx:/home/work/open-falcon
将目录下的 open-falcon 拷贝到客户端,(二进制程序)
1
scp open-falcon root@xxxx:/home/work/
修改 agent/config/ 下的 cfg.json 文件,heartbeat模块和transfer模块下的ip地址,将
127.0.0.1:6030和127.0.0.1:18433两个地址中的127.0.0.1改成 open-falcon server 的地址1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54{
"debug": true, # 控制一些debug信息的输出,生产环境通常设置为false
"hostname": "", # agent采集了数据发给transfer,endpoint就设置为了hostname,默认通过`hostname`获取,如果配置中配置了hostname,就用配置中的
"ip": "", # agent与hbs心跳的时候会把自己的ip地址发给hbs,agent会自动探测本机ip,如果不想让agent自动探测,可以手工修改该配置
"plugin": {
"enabled": false, # 默认不开启插件机制
"dir": "./plugin", # 把放置插件脚本的git repo clone到这个目录
"git": "https://github.com/open-falcon/plugin.git", # 放置插件脚本的git repo地址
"logs": "./logs" # 插件执行的log,如果插件执行有问题,可以去这个目录看log
},
"heartbeat": {
"enabled": true, # 此处enabled要设置为true
"addr": "127.0.0.1:6030", # hbs的地址,端口是hbs的rpc端口
"interval": 60, # 心跳周期,单位是秒
"timeout": 1000 # 连接hbs的超时时间,单位是毫秒
},
"transfer": {
"enabled": true,
"addrs": [
"127.0.0.1:18433"
], # transfer的地址,端口是transfer的rpc端口, 可以支持写多个transfer的地址,agent会保证HA
"interval": 60, # 采集周期,单位是秒,即agent一分钟采集一次数据发给transfer
"timeout": 1000 # 连接transfer的超时时间,单位是毫秒
},
"http": {
"enabled": true, # 是否要监听http端口
"listen": ":1988",
"backdoor": false
},
"collector": {
"ifacePrefix": ["eth", "em"], # 默认配置只会采集网卡名称前缀是eth、em的网卡流量,配置为空就会采集所有的,lo的也会采集。可以从/proc/net/dev看到各个网卡的流量信息
"mountPoint": []
},
"default_tags": {
},
"ignore": { # 默认采集了200多个metric,可以通过ignore设置为不采集
"cpu.busy": true,
"df.bytes.free": true,
"df.bytes.total": true,
"df.bytes.used": true,
"df.bytes.used.percent": true,
"df.inodes.total": true,
"df.inodes.free": true,
"df.inodes.used": true,
"df.inodes.used.percent": true,
"mem.memtotal": true,
"mem.memused": true,
"mem.memused.percent": true,
"mem.memfree": true,
"mem.swaptotal": true,
"mem.swapused": true,
"mem.swapfree": true
}
}开启服务
1
2
3
4./open-falcon start agent
./open-falcon stop agent
./open-falcon check #检查自己的agent模块是否开启
./open-falcon monitor agent #查看agent的启动日志有防火墙的需要开启防火墙的 1988 端口,push 数据所用
查看agent 展示页面
本地浏览器 查看 localhost:1988 ,并在server 端查看是否增加此endpoint
四、安装问题排查
如何确定数据是否正常收集: 数据收集相关问题
如何验证[绘图数据]收集是否正常:
数据链路是:agent->transfer->graph->query->dashboard。graph有一个http接口可以验证agent->transfer->graph这条链路,比如graph的http端口是6071,可以这么访问验证:curl http://127.0.0.1:6071/history/$endpoint/$counter
$endpoint和$counter是变量
如何验证[报警数据]收集是否正常:
数据链路是:agent->transfer->judge,judge有一个http接口可以验证agent->transfer->judge这条链路,比如judge的http端口是6081,可以这么访问验证:curl http://127.0.0.1:6081/history/$endpoint/$counter
$endpoint和$counter是变量
如果调用上述接口返回空值,则说明agent没有上报数据、或者transfer服务异常。
相关日志文件:
server:
- dashboard/var/app.log
agent:
- agent/logs/agent.log
五、添加监控
1.创建 HostGroup 右上角编辑名字点击添加,在hostgroup 中添加 hosts。
如下图: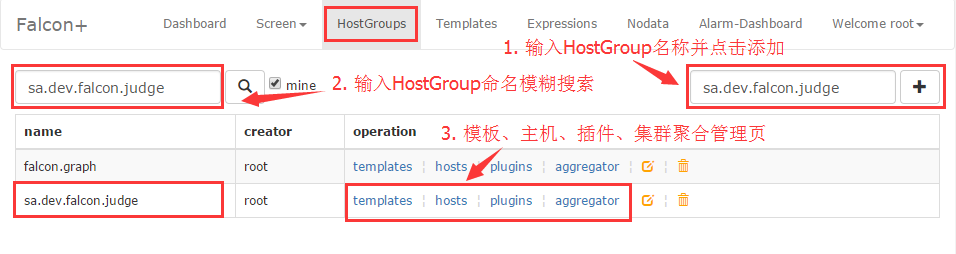
2.创建一个模板,在 condition 中设置规则
如下图: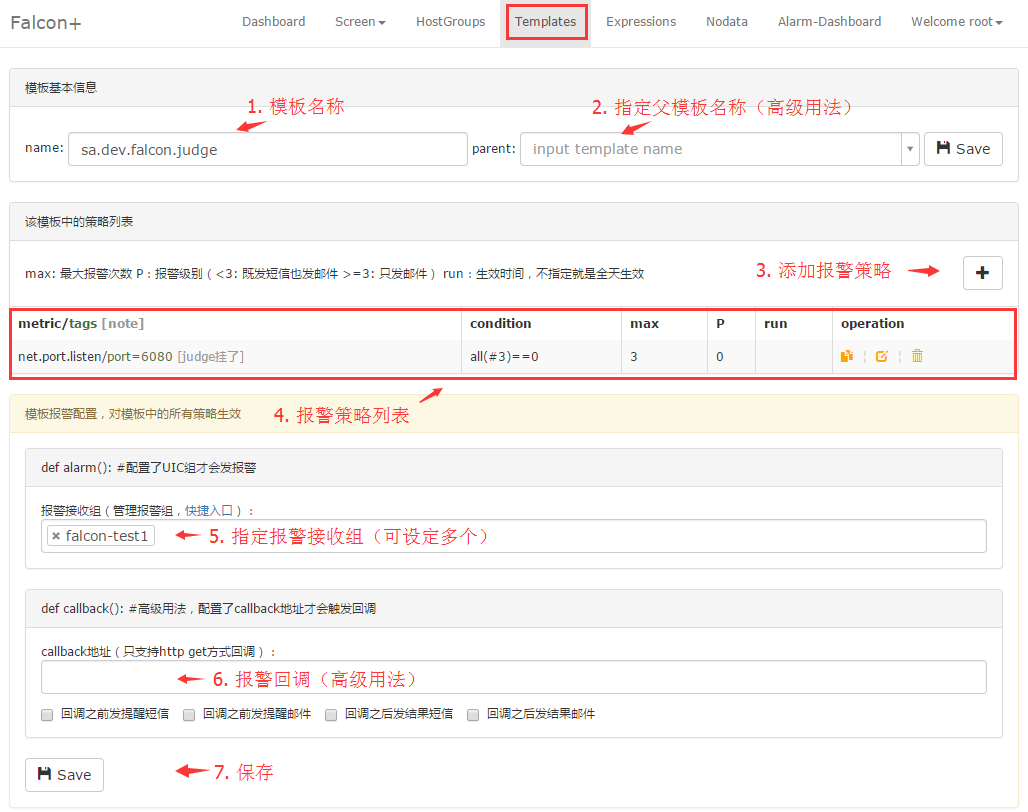
如果是自定义的 push 的metric 可能搜索不到,直接写就可以
策略中 all(#3) 中的3代表的是最新的三个点。该数字默认不能大于10,大于10将当作10处理,即只计算最新10个点的值。
all 是函数策略:
1 | all(#3): 最新的3个点都满足阈值条件则报警 |
- HostGroup 模块中绑定模板到 HostGroup 上,配置完成后,如发生报警,可在 Alarm-Dashboard 看到。
如下图:
六、自定义 push 数据
1.shell 模板
1 | 注意,http request body是个json,这个json是个列表 |
例:从 proc 拿数据 push 到server1
2
3
4
5
6
7
8
9
10
11[root@centos69 scripts]# sh active_memory.sh
success
[root@centos69 scripts]# cat active_memory.sh
!/bin/bash
ts=`date +%s`;
value=`cat /proc/meminfo |grep Active: |awk '{print $2}'`
curl -X POST -d "[{\"metric\": \"mem.active\", \"endpoint\": \"centos69\", \"timestamp\": $ts,\"step\": 60,\"value\": $value,\"counterType\": \"GAUGE\",\"tags\": \"loc=hefei\"}]" http://127.0.0.1:1988/v1/push
[root@centos69 scripts]# cat /etc/crontab
*/1 * * * * root sh /root/software/scripts/active_memory.sh
2.python 模板
1 | #!-*- coding:utf8 -*- |
3.API 详解
- metric: 最核心的字段,代表这个采集项具体度量的是什么, 比如是cpu_idle呢,还是memory_free, 还是qps
- endpoint: 标明Metric的主体(属主),比如metric是cpu_idle,那么Endpoint就表示这是哪台机器的cpu_idle
- timestamp: 表示汇报该数据时的unix时间戳,注意是整数,代表的是秒
- value: 代表该metric在当前时间点的值,float64
- step: 表示该数据采集项的汇报周期,这对于后续的配置监控策略很重要,必须明确指定。
- counterType: 只能是COUNTER或者GAUGE二选一,前者表示该数据采集项为计时器类型,后者表示其为原值 (注意大小写)
- GAUGE:即用户上传什么样的值,就原封不动的存储
- COUNTER:指标在存储和展现的时候,会被计算为speed,即(当前值 - 上次值)/ 时间间隔
- tags: 一组逗号分割的键值对, 对metric进一步描述和细化, 可以是空字符串. 比如idc=lg,比如service=xbox等,多个tag之间用逗号分割
上述7个字段是必须的。