前言
关于 Linux 内存管理方面一些文章和书籍中都使用大量的篇幅去讲解,本篇文章主要从进程如何使用内存和物理内存如何管理的两个角度出发,去看 linux 系统是如何管理内存的。由于涉及的点比较多,并且本人技术水平有限,一些内容不会讲的太过深入,一些我比较感兴趣的点,我们会在后续文章中进一步学习。
进程如何使用内存
进程地址空间
所有进程的执行都需要占用一定的内存,那么进程是怎么使用机器上的内存的呢,linux 系统上每一个进程都有自己可以访问的内存地址空间,对应 4G(32位系统) 大小。第一部分为“用户空间”,用来映射其整个进程空间(0x0000 0000-0xBFFF FFFF)即3G字节的虚拟地址;第二部分为“内核空间”,用来映射(0xC000 0000-0xFFFF FFFF)1G字节的虚拟地址。可以看出Linux系统中每个进程的页面目录的第二部分是相同的,所以从进程的角度来看,每个进程有4G字节的虚拟空间, 较低的3G字节是自己的用户空间,最高的1G字节则为与所有进程以及内核共享的系统空间。4G 是进程认为的虚拟地址空间,一个进程实际占用的物理空间通过实际分配的计算。虚拟内存通过页表映射到物理内存,两个进程也可以通过映射到统一物理地址实现内存共享。
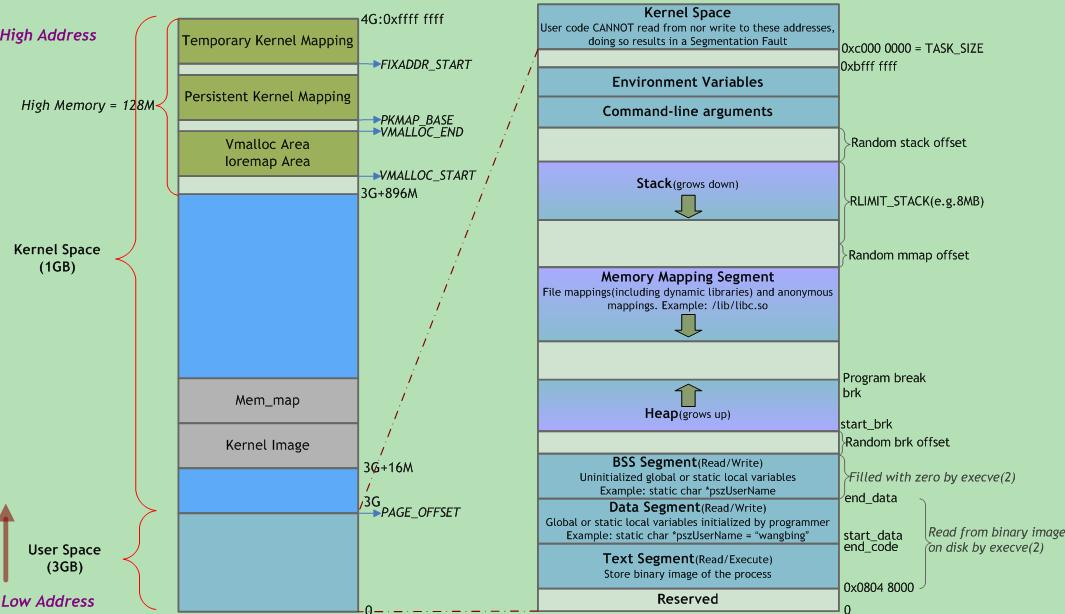
上图左边展示的是内核内存地址空间(1G),右边展示的是用户内存地址空间,每当进程切换用户空间就会跟着变化;而内核空间是由内核负责映射,它并不会跟着进程改变,是固定的,进程访问内核空间的方式:系统调用和中断。内核空间地址有自己对应的页表(init_mm.pgd),用户进程各自有不同的页表。
上图右边讲解了进程地址空间中使用的数据段种类:
- 代码段(text):代码段是用来存放可执行文件的操作指令,也就是说是它是可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入(修改)操作——它是不可写的。
- 数据段(data):数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
- BSS 段:BSS段包含了程序中未初始化的全局变量,在内存中 bss段全部置零。
- 堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
- 栈(stack):栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
虚拟内存在内核中的实现
进程在内核中以 task_struct 结构体表示,task_struct 中的 mm_struct 结构体用来存放进程地址空间的所有信息。虚拟内存的最小单位是 vma 结构体,其中每一块内存都通过 vm_area_struct 来存放。vma 中记录开始和结束位置,vma 成链表结构存放在 mm_struct 中,另外还有红黑树提供快速定位查找。如下图所示: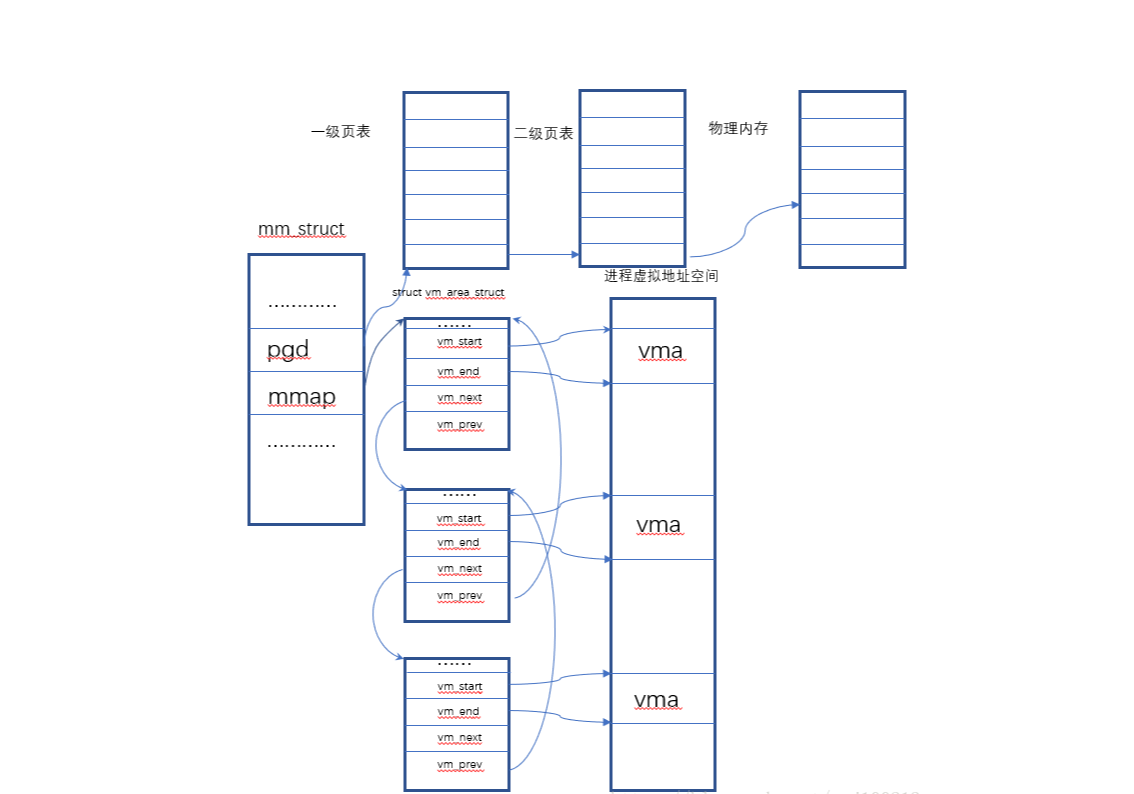
系统上查看进程内存
上面介绍了进程使用内存的一些理论,那么能否在系统上直观的看到进程使用了哪些内存呢? 通过/proc/PID/maps 或者 pmap 命令可以看到进程使用 VMA 映射了的内存区域和访问权限。通过/proc/PID/smaps 可以看到更详细的信息。
1 | # pmap -x 5371 |
第5列代表执行权限,r,w,x不必说,p=私有 s=共享。在Mapping 列可以看到所映射的文件名。对有名映射而言,是映射的文件名,对匿名映射来说,是此段内存在进程中的作用。[stack]表示本段内存作为栈来使用,[heap]作为堆来使用,其他情况则为无。
其中代码段是 rx 权限,数据段和 bss 有 rw 权限,堆栈可能有 rwx 的权限。上述 C 库所占有的内存是共享的不可写的,实际属于这个进程的私有物理进程很少,这样可以减少大量内存。
进程各文件以及进程内存地址空间结构如下图:
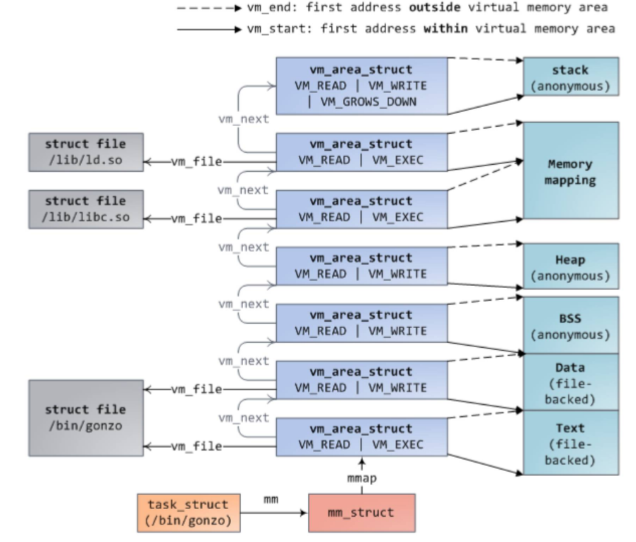
进程用来申请内存的函数
创建进程等进程相关操作都需要分配内存给进程。这时进程申请和获得的不是物理地址,仅仅是虚拟地址。实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由“请页机制”产生“缺页”异常,从而进入分配实际页框的程序。该异常是虚拟内存机制赖以存在的基本保证,它会告诉内核去为进程分配物理页,并建立对应的页表,这之后虚拟地址才实实在在的映射到了物理地址上。
进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
创建进程fork()、程序载入execve()、映射文件mmap()、动态内存分配malloc()/brk()等进程相关操作都需要分配内存给进程。不过这时进程申请和获得的还不是实际内存,而是虚拟内存,准确的说是“内存区域”。进程对内存区域的分配最终都会归结到do_mmap()函数上来(brk调用被单独以系统调用实现,不用do_mmap()),
内核使用do_mmap()函数创建一个新的线性地址区间。但是说该函数创建了一个新VMA并不非常准确,因为如果创建的地址区间和一个已经存在的地址区间相邻,并且它们具有相同的访问权限的话,那么两个区间将合并为一个。如果不能合并,那么就确实需要创建一个新的VMA了。但无论哪种情况, do_mmap()函数都会将一个地址区间加入到进程的地址空间中--无论是扩展已存在的内存区域还是创建一个新的区域。
同样,释放一个内存区域应使用函数do_ummap(),它会销毁对应的内存区域。
malloc利用堆动态分配,实际上是调用brk()系统调用,该调用的作用是扩大或缩小进程堆空间(它会修改进程的brk域)。如果现有的内存区域不够容纳堆空间,则会以页面大小的倍数为单位,扩张或收缩对应的内存区域,但brk值并非以页面大小为倍数修改,而是按实际请求修改。因此Malloc在用户空间分配内存可以以字节为单位分配
共享内存实现进程间通讯
进程间通讯(IPC)的实现方式有很多种,如管道、消息队列、共享内存、信号量、套接口等等。共享内存是运行在同一台机器上的进程间通信最快的方式,因为数据不需要在不同的进程间复制。通常由一个进程创建一块共享内存区,其余进程对这块内存区进行读写。得到共享内存有两种方式:映射/dev/mem 设备和内存映像文件。前一种方式不给系统带来额外的开销,但在现实中并不常用,因为它控制存取的将是实际的物理内存,在Linux系统下,这只有通过限制Linux系统存取的内存才可以做到,这当然不太实际。常用的方式是通过shmXXX 函数族来实现利用共享内存进行存储的。
64位系统地址空间
64 位系统结果怎样呢? 64 位系统是否拥有 2^64 的地址空间吗?
事实上, 64 位系统的虚拟地址空间划分发生了改变:
地址空间大小不是2^32,也不是 2^64 ,而一般是 2^48 。因为并不需要 2^64 这么大的寻址空间,过大空间只会导致资源的浪费。64位Linux一般使用48位来表示虚拟地址空间,40位表示物理地址,
这可通过 /proc/cpuinfo 来查看
address sizes : 40 bits physical, 48 bits virtual其中,0x0000000000000000~0x00007fffffffffff 表示用户空间, 0xFFFF800000000000~ 0xFFFFFFFFFFFFFFFF 表示内核空间,共提供 256TB(2^48) 的寻址空间。
这两个区间的特点是,第 47 位与 48~63 位相同,若这些位为 0 表示用户空间,否则表示内核空间。用户空间由低地址到高地址仍然是只读段、数据段、堆、文件映射区域和栈;
从物理内存角度看内存
内存页及虚拟内存到物理内存的映射
Linux内核管理物理内存是通过分页机制实现的,它将整个内存划分成无数个4k(在i386体系结构中)大小的页,从而分配和回收内存的基本单位便是内存页了。利用分页管理有助于灵活分配内存地址,因为分配时不必要求必须有大块的连续内存,系统可以东一页、西一页的凑出所需要的内存供进程使用。虽然如此,但是实际上系统使用内存时还是倾向于分配连续的内存块,因为分配连续内存时,页表不需要更改,因此能降低TLB的刷新率(频繁刷新会在很大程度上降低访问速度)。
物理页在系统中由页结构struct page描述,系统中所有的页面都存储在数组mem_map[]中,可以通过该数组找到系统中的每一页(空闲或非空闲)。而其中的空闲页面则可由上述提到的以伙伴关系组织的空闲页链表(free_area[MAX_ORDER])来索引。
虚拟内存通过页表的映射来找到真实的物理内存,即从进程能理解的线性地址(linear address)映射到存储器上的物理地址(phisical address)。页表是固定存在在cache中的,地址映射必须要有硬件支持,mmu(内存管理单元)就是这个硬件。并且需要有cache来保存页表,这个cache就是TLB(Translation lookaside buffer)。另外也存在物理页到页表项的反向映射,反向映射是在回收内存页时用的。
页表映射其实就是通过多级数组实现的,内核从2.6.11开始采用了四级页表,之前是三级页表和二级页表。线性地址 (比如00007fffbf2ce000)转换为二进制后,最高10位对应目录项地址,中间10位对应页表项地址,最后12位对应key 的 value 中存放物理页的起始地址。
为什么要使用多级页表,而不是直接将线性地址映射到物理地址呢?多级页表好处如下:
- 多级页表不需要保证页目录项和页表项物理内存连续。
- 使用多级页表可以节省页表内存。使用一级页表,需要连续的内存空间来存放所有的页表项。多级页表通过只为进程实际使用的那些虚拟地址内存区请求页表来减少内存使用量。
- 例:二级页表中,页目录项大小为 4K 存放1024 个4byte(正好32位) 页表项也是 4K 存放 1024 个 4byte 。也就是说 我只用8k 就能映射 1024 个 页(4K)内存
当然使用页表也是有劣势的,需要多次访问内存,增加了花费的时间,TLB 就是为了减少这个时间的。三级页表图示如下: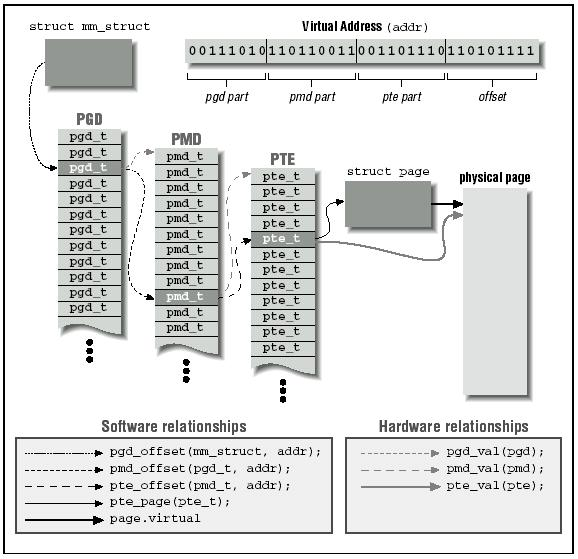
物理内存的 ZONE
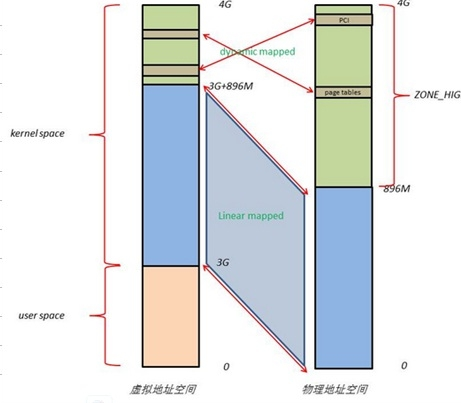
之前讲到每个进程都有自己的内存地址空间,0-3G对于每个进程都是不同的,3-4G的内核空间是相同的。那么内核怎么使用这1G的空间访问所有的物理内存呢?由于开启了分页机制,内核想要访问物理地址空间的话,必须先建立映射关系,然后通过虚拟地址来访问。为了能够访问所有的物理地址空间,就要将全部物理地址空间映射到1G的内核线性空间中,这显然不可能。
x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和 ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,当系统物理内存较大时,超过896M的内存区域,内核就无法直接通过线性映射直接访问了。这部分内存被称作high memory。其中,64位系统下不会有high memory,因为64位虚拟地址空间非常大(分给kernel的也很大),完全能够直接映射全部物理内存。
在 32 位系统中(内存大于896M时):
- ZONE_DMA 的范围是0~16M,该区域的物理页面专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA。
- ZONE_NORMAL 的范围是16M~896M,该区域的物理页面是内核能够直接使用的。ZONE_NORMAL和内核线性空间存在直接映射关系,映射关系写死的,不需要像用户进程地址一样通过页表动态映射。所以内核会将频繁使用的数据如kernel代码、GDT、IDT、PGD、mem_map数组等放在ZONE_NORMAL里。为什么是896,可能是一个经验值吧…
- ZONE_HIGHMEM 的范围是896M~结束,该区域内核不能直接使用。内核使用剩下的128M线性地址空间不足以完全映射所有的ZONE_HIGHMEM,Linux采取了动态映射的方法,即按需的将ZONE_HIGHMEM里的物理页面映射到kernel space的最后128M线性地址空间里,使用完之后释放映射关系,以供其它物理页面映射。虽然这样存在效率的问题,但是内核毕竟可以正常的访问所有的物理地址空间了。比如,当内核要访问I/O设备存储空间时,就使用ioremap()将位于物理地址高端的mmio区内存映射到内核空间的vmalloc-area中,在使用完之后便断开映射关系。
现在让我们忘记进程地址空间的图,看一下内核地址空间是怎么映射的:
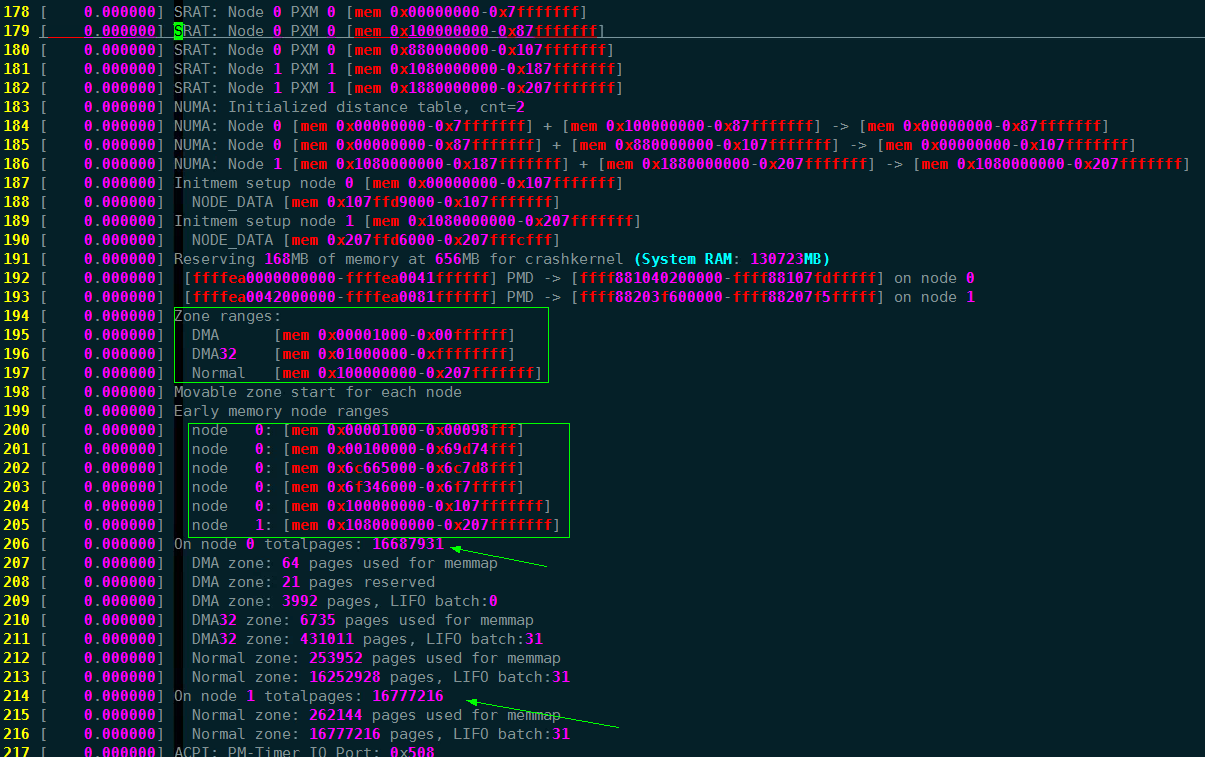
物理内存的 Zone 的划分 、page 数量 在开机的时候就已经决定了,通过dmesg 日志可以看到每一个Zone 的物理地址划分,显然在numa 架构中,只有第一个node 有DMA Zone。
伙伴系统buddy 和 slab
linux 是通过页管理物理内存的,内核分配物理页面时为了尽量减少不连续情况,采用了“伙伴”关系来管理空闲页面。Linux中空闲页面的组织和管理利用了伙伴关系,因此空闲页面分配时也需要遵循伙伴关系,最小单位只能是2的幂倍页面大小。内核中分配空闲页面的基本函数是get_free_page/get_free_pages,它们或是分配单页或是分配指定的页面(2、4、8…512页)。内存分配 API 如kmalloc/vmalloc/kmap以及maolloc都是基于Buddy算法之上进行二级内存管理,这些API不直接面对物理内存(内存条)。
通过 /proc/buddyinfo 可以看到机器上各个order 中内存块剩余的数量。
伙伴系统适合分配大的连续内存,对于小的内存申请,例如几个字节几十个字节,分配一整个页框太过于浪费,并且如果需要频繁的获取/释放并不大的连续物理内存怎么办,如几十字节几百字节的获取/释放,这样的话用buddy就不太合适了,所以内核引入了一种新的数据结构:slab。slab 是基于buddy 的,前者是对后者的细化。
slab 的分配机制:
slab分配器是基于对象进行管理的,所谓的对象就是内核中的数据结构(例如:task_struct,file_struct 等)。相同类型的对象归为一类,每当要申请这样一个对象时,slab分配器就从一个slab列表(slabs_partial、slabs_full、slabs_empty)中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免内部碎片。slab分配器并不丢弃已经分配的对象,而是释放并把它们保存在内存中。slab分配对象时,会使用最近释放的对象的内存块,因此其驻留在cpu高速缓存中的概率会大大提高。
在/proc/slabinfo文件中有对内核slab情况的记录,如下图:
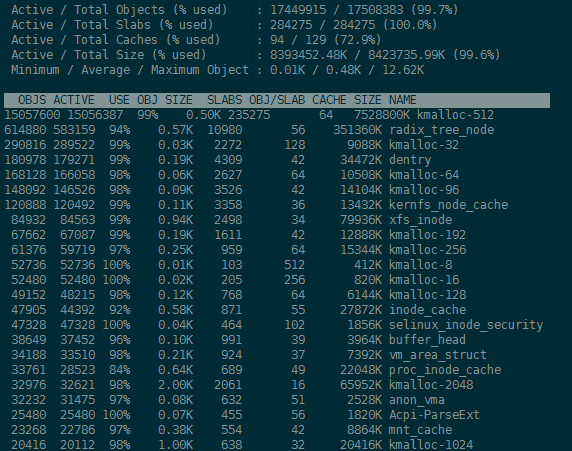
从上图可以看到内核常规结构的小块内存的slab分配情况,如UDPv6/TCPv6等,其中<active_objs> <num_objs>
物理内存的申请函数
物理内存的分配函数:
- get_free_pages()或alloc_pages()从normal区域的buddy系统中 使用页框分配器中获得页框。
- kmem_cache_alloc()或kmalloc使用slab 分配器为专用或通用对象分配块,从内核内存分配的角度来讲,kmalloc可被看成是get_free_page(s)的一个有效补充,内存分配粒度更灵活了。不过可申请内存的大小有限。
- vmalloc() 或 vmalloc_32()从 VMALLOC区域 vmalloc_start(892M+8M)~vmalloc_end之间获得一块非连续内存。vmalloc 优先分配的是high_memory。
- 即时使用了slab 和 buddy ,但还是无法彻底解决内存外部分片的情况,vmalloc 就是为了利用这些不连续的内存块。vmalloc 申请内存类似进程申请的虚拟内存,需要将内存虚拟地址进行映射。
- vmalloc 申请的虚拟内存区域用 vm_struct 结构体表示 ,不是vma 不要弄混。
几种物理内存分配函数的比较:
| 函数 | 分配原理 | 最大内存 | 其他 |
|---|---|---|---|
| __get_free_pages | 直接对页框进行操作 | 4MB | 适用于分配较大量的连续物理内存 |
| kmem_cache_alloc | 基于slab机制实现 | 128KB | 适合需要频繁申请释放相同大小内存块时使用 |
| kmalloc | 基于kmem_cache_alloc实现 | 128KB | 最常见的分配方式,需要小于页框大小的内存时可以使用 |
| vmalloc | 建立非连续物理内存到虚拟地址的映射 | 物理不连续,适合需要大内存,但是对地址连续性没有要求的场合 | |
| dma_alloc_coherent | 基于__alloc_pages实现 | 4MB | 适用于DMA操作 |
| ioremap | 实现已知物理地址到虚拟地址的映射 | 适用于物理地址已知的场合,如设备驱动 | |
| alloc_bootmem | 在启动kernel时,预留一段内存,内核看不见 | 小于物理内存大小,内存管理要求较高 |
两种角度如何联系起来
前面我们介绍了进程是如何使用虚拟内存的,也介绍了物理内存在linux 内核下是如何管理的。那么如何将两个角度联系起来呢,简单来说两者就是通过虚拟内存到物理内存的映射联系起来的。当虚拟内存没有映射到物理内存的时候,发生page_fault 申请物理内存。
下面我们将两个角度联系起来画一张图展示: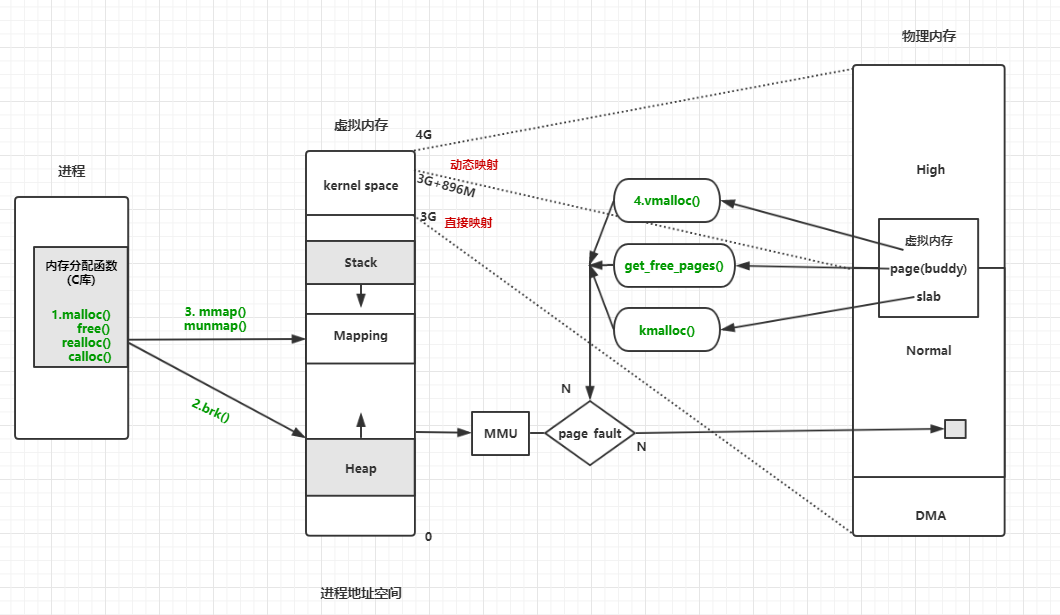
- 进程调用 libc 库中的函数申请内存;
- libc 库函数调用内核系统调用申请进程虚拟内存地址空间
- 虚拟内存通过MMU 映射找到物理内存
- 映射没有建立时,内核调用函数分配物理内存。(各种函数通过gfp_mask flag 来决定在哪个ZONE 优先申请。)
从用户态到内核态
我们知道linux 有用户态和内核态的概念,像分配物理内存,从父进程拷贝相关信息,拷贝设置页目录、页表等,这些操作显然不能随便让任何程序都可以做,于是就产生了特权级别的概念,与系统相关的一些特别关键性的操作必须由高级别的程序来完成,这样可以做到集中管理,减少有限资源的访问和使用冲突。
上面我们讲到,进程使用libc库函数申请内存时,会调用内核的系统调用,从用户态到内核态的转换就是通过系统调用实现的(主要是系统调用,还有中端和异常,其实系统调用也是通过软中断实现的)。
Linux的系统调用通过int0x80实现,用系统调用号来区分入口函数,因为用户栈和内核栈不在同一空间,所以使用寄存器传递参数。
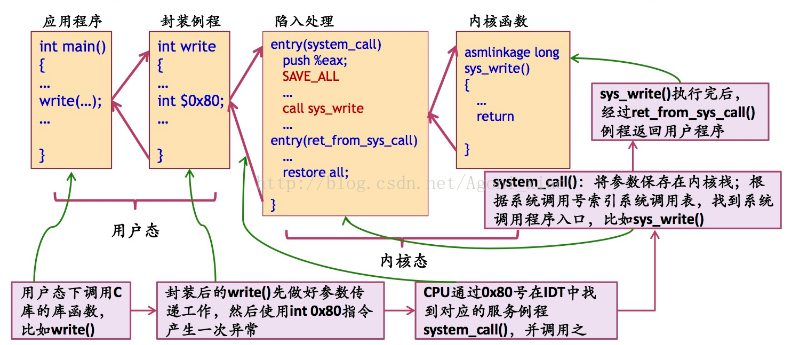
操作系统实现系统调用的基本过程是:
- 应用程序调用库函数(API);
- API将系统调用号存入EAX,然后通过中断调用使系统进入内核态;
- 内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
- 系统调用完成相应功能,将返回值存入EAX,返回到中断处理函数;
- 中断处理函数返回到API中;
- API将EAX返回给应用程序。
书籍推荐及相关链接
链接:
- slab分配: https://blog.csdn.net/yunsongice/article/details/5272715
- 内存回收:https://www.cnblogs.com/tolimit/p/5435068.html
书籍:
- 入门:《Linux内核设计与实现》
- 进阶:《深入理解Linux内核